Java的Stream编程
自从Java 8将函数式编程引入语言后,该语言通过Lambda表达式和Stream库两者的结合,展现了全新的编码方式。实现了简洁,高效,以及类似声明式的编码风格。
举个例子,如我们有个集合里面存放的是颜色的标签,我们想在集合中找出以“b”字符开头的标签,并进行排序,然后转换成大写字符标签,最后输出。如果用Java 8以前的编码方式,我们会进行多次轮询,最后输出结果:
public static void main(String[] args) {
List<String> colors = Arrays.asList("blue", "green", "brown", "grey", "red", "white", "black", "beige", "purple");
List<String> filteredAndSortedColors = new ArrayList<>();
for (String color : colors) {
if (color.startsWith("b")) {
filteredAndSortedColors.add(color);
}
}
Collections.sort(filteredAndSortedColors);
for (String color : filteredAndSortedColors) {
System.out.println(color.toUpperCase());
}
}
如果用Java 8的Lambda、Stream来实现,则代码会更加简洁、易懂,执行效率也会提高:
public static void main(String args[]) {
Stream.of("blue", "green", "brown", "grey", "red", "white", "black", "beige", "purple")
.filter(s -> s.startsWith("b"))
.sorted()
.map(s -> s.toUpperCase())
.forEach(System.out::println);
}
Go的Stream编程
go语言中函数是第一公民,理论上我们可以实现更简洁的Stream框架。Stream的核心有以下几个方面:
- 基于流的操作
- 支持并行计算
- 声明式编程风格
基于流的操作
是指数据不断流入,对每个数据依次执行相应的操作并得到最后结果,然后再处理下一个数据,直到所有数据处理完成,最终程序结束。举例说明比较直观,我们有数据集Z,对应操作A,B,C。以前我们对数据的处理方式是对整个数据集Z进行遍历执行操作A得到数据集Z1,然后再对数据集Z1进行遍历执行操作B得到Z2,遍历Z2执行操作C得到最后结果Z3,这里我们有多少操作就需要遍历多少次。基于流的操作方式针对数据集只需遍历一次,对数据集Z进行遍历,对遍历到的第一个数据执行A、B、C三个操作,然后依次对后面的数据执行同样的操作,直至遍历完成。
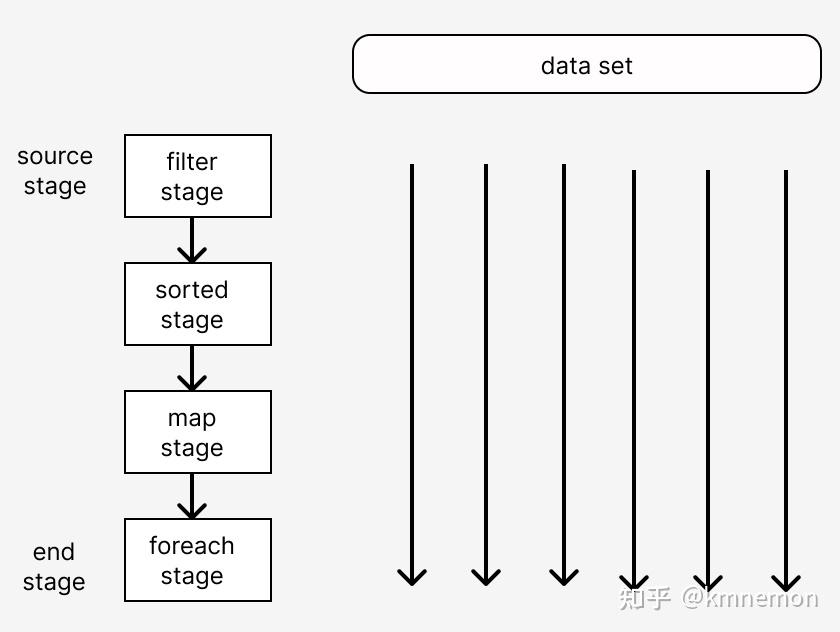
在实现中这里有两个难点:
- 每个stage怎么连接起来,操作怎么连接起来?
- 操作怎样惰性求值?
在go stream的实现中,建立了一个pipeline结构体代表stage,这个结构体是一个双向链表同时指向前一个和后一个stage。在每个pipeline初始化的时候通过链表指针指向了前后的stage,这样就把所有操作的stage连接起来。
type pipeline[T any] struct {
previousStage *pipeline[T]
nextStage *pipeline[T]
sourceStage *pipeline[T]
depth int
streamOpFlag stateType
streamSink sink[T]
sourceData []T
}
func (p *pipeline[T]) init(previousStage *pipeline[T], opFlag stateType, sink sink[T]) {
if opFlag == head {
p.previousStage = nil
p.sourceStage = p
p.depth = 0
} else {
p.previousStage = previousStage
p.previousStage.nextStage = p
p.sourceStage = previousStage.sourceStage
p.depth = p.previousStage.depth + 1
p.streamSink = sink
}
p.streamOpFlag = opFlag
}
那我们操作怎么惰性求值的呢?注意在pipeline结构体里面有个sink[T]接口,实现这个接口的结构体含有具体的操作。我们以map操作为例,map操作里的pipeline实现了mapSink[T any]这个结构体,结构体里面mapper函数就是具体对数据集里数据的操作。
type sink[T any] interface {
begin(int)
accept(T)
end()
isCancellationWasRequested() bool
cancellationRequested() bool
canParallel() bool
setDownStreamSink(sink[T])
}
type mapSink[T any] struct {
mapper func(T) T
downstream sink[T]
}
在最后一个stage里,我们会调用evaluate函数,这个函数会对所有的sink结构体进行叠加,这里只进行wrap操作,等所有sink都叠加完成后,调用copyInto函数遍历每个数据进行sink操作的真正执行。这样我们就完成了惰性求值。
func (p *pipeline[T]) evaluate(s sink[T]) {
p.copyInto(p.wrapSink(s), p.sourceStage.sourceData)
}
func (p *pipeline[T]) wrapSink(sink sink[T]) sink[T] {
for ; p.depth > 0; p = p.previousStage {
sink = p.opWrapSink(sink)
}
return sink
}
func (p *pipeline[T]) copyInto(wrapSink sink[T], slice []T) {
....
wrapSink.begin(len(slice))
if !wrapSink.isCancellationWasRequested() {
for _, v := range slice {
wrapSink.accept(v)
}
} else {
for _, v := range slice {
if wrapSink.cancellationRequested() {
break
}
wrapSink.accept(v)
}
}
wrapSink.end()
}
支持并行计算
有了上面基于流的操作,以及go协程的强大,并行计算就采用协程来实现。在go stream中新增方法Parallel()来表示要对数据集进行并行计算。在并行计算中监测当前平台具备多少核心的CPU,通过把数据集按核心数等分,调用go协程并行执行流的操作来加快整个计算速度。
func (s *parallelSink[T]) end() {
if s.canparallel {
var wg sync.WaitGroup
cores := runtime.NumCPU()
for _, slice := range splitSlice(s.list, cores) {
wg.Add(1)
go func(slice []T) {
defer wg.Done()
for _, v := range slice {
s.downstream.accept(v)
}
}(slice)
}
wg.Wait()
}
s.downstream.end()
}
声明式编程风格
stream带来编程风格的转变,便是这种声明式的编程风格,你告诉程序需要对数据集进行什么样的操作,比如filter,sort,然后你再给它需要的规则filter里哪些特征的数据为true,sort里数据大小比较规则等,不用关注内部算法细节,框架自己完成整个计算过程。这里我们通过stream接口定义了整个操作集。
type stream[T any] interface {
Parallel() stream[T]
Map(func(T) T) stream[T]
Reduce(func(T, T) T) T
ReduceWithInitValue(T, func(T, T) T) T
ForEach(func(T))
Sorted() stream[T]
SortedWith(func(T, T) bool) stream[T]
Filter(func(T) bool) stream[T]
Limit(int) stream[T]
FindFirst() T
ToList() []T
Distinct() stream[T]
DistinctWith(func(T, T) bool) stream[T]
}
上面我针对go stream这个框架,介绍了基于流的操作,怎样支持并行计算,以及声明式编程风格。这个框架我在实现时并行计算部分实现采用了比较基础的方式,还可以再进一步实现更多的功能,改进算法得到更高的效率。大家有兴趣可以一起研究。
该项目开源地址:gostream
基于Go-1.18实现