上一篇文章《理解响应式编程(reactive programming)》我们谈到响应式编程四个核心概念:
发布者(The Publisher): 发布者就是数据的生产者,这个是为系统生产数据的组件,这里的服务B就是一个发布者,他收到服务A的请求后就开始生产数据。
订阅者(The Subscriber): 订阅者订阅发布者生产的数据。这里服务A就是订阅者,他订阅来自服务B的数据。
订阅过程(The Subscription):订阅过程是一份服务之间的合约(contract),它被用于订阅者获取数据,或者取消订阅。
处理者(The Processor):处理者是一个响应式实体,他能够消费发布者的数据,并进行再加工,然后发布自己的数据,上面的例子并未体现这层逻辑。举个例子,排序处理者,他可以作为订阅者获取发布者的随机序数据,然后进行排序,然后作为发布者生产出排序后的数据。
一个典型的响应式交互如下: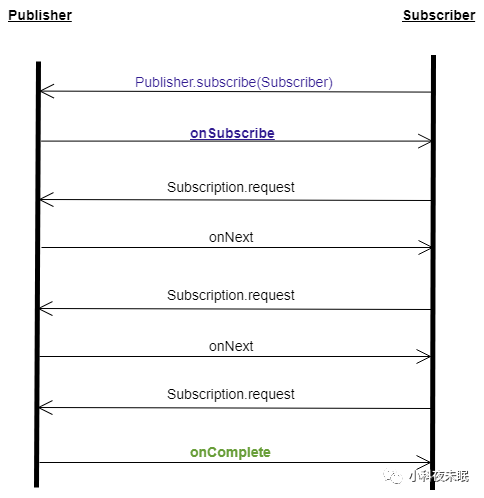
订阅者和发布者签订订阅契约(Publisher.subscribe),一旦契约签订完成,订阅者向发布者请求数据(Subscription.request),发布者准备好数据后传输数据给订阅者(调用订阅者onNext),订阅者再次请求新数据(request),直到发布者告诉订阅者数据已经发送完成(onComplete),本次契约完成。
Reactive REST Appplication
现在我们使用WebFlux开始构建一个简单的响应式应用.
- 使用一个简单的领域模型-Employee
- 使用RestController返回发布者生产的数据
- 使用WebClient构建订阅者获取发布者数据
WebFlux Maven依赖如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
发布者(Publisher)
WebFlux底层使用Project Reactor,所以我们这里使用Project Reactor的命名来介绍。
发布者有两个类型:
- Mono类型表示生产0个或者至多1个数据
- Flux类型表示生产多个数据
示例代码分为三层分别是:
- controller-获取REST请求,并返回订阅数据
- model-包含Employee领域模型
- repository-构建内存数据库(采用HashMap)
controller:
可以看到方法返回类型为Mono或者Flux,表示生产者会生产对应类型个数的数据
@RestController
@RequestMapping("/employees")
public class EmployeeController {
private static final Logger logger = LoggerFactory.getLogger(EmployeeController.class);
private final EmployeeRepository employeeRepository;
public EmployeeController(EmployeeRepository employeeRepository) {
this.employeeRepository = employeeRepository;
}
@GetMapping("/{id}")
private Mono<Employee> getEmployeeById(@PathVariable String id) {
logger.debug("getEmplyeeById controller get called");
return employeeRepository.findEmployeeById(id);
}
@GetMapping
private Flux<Employee> getAllEmployees() {
logger.debug("getAllEmployees controller get called");
return employeeRepository.findAllEmployees();
}
@PostMapping("/update")
private Mono<Employee> updateEmployee(@RequestBody Employee employee) {
return employeeRepository.updateEmployee(employee);
}
}
model:
很简单的领域模型Employee包含id和name两个字段
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Employee {
private String id;
private String name;
// standard getters and setters
}
repository:
这里不是重点记住使用HashMap内存数据库.
@Repository
public class EmployeeRepository {
static Map<String, Employee> employeeData;
static Map<String, String> employeeAccessData;
...
}
订阅者(Subscriber)
订阅者订阅发布者数据,有三种情况会通知订阅者:1.发布者准备好数据后,2.错误发生时,3.发布者生产完数据.
所以订阅者有三个数据通道,每一个通道都是订阅者的内部方法:
- OnNext-当发布者有1个或多个数据生产出来会调用这个方法
- OnError-当发布者在生产过程中出现错误会调用这个方法,注意当这个方法被调用,发布者将不再生产数据。
- OnComplete-当发布者数据生产完成会调用订阅者这个方法。
订阅者我们使用WebClient是一个非阻塞客户端并支持响应式流。
在订阅者服务,我们自定义consumeMono方法来订阅单个数据,consumeFlux订阅多个数据。
- 在consumeMono方法里面,我们在签订契约的时候(employeeMono.subscribe)只定义了OnNext数据通道(employee -> logger.debug(“Employee: {}”, employee))
- 在consumeFlux方法里,我们在签订契约的时候(employeeFlux.subscribe)定义了上述的三个数据通道:
OnNext-employee -> logger.debug(“Employee: {}”, employee)
OnError-err -> err.printStackTrace()
OnComplete-() -> logger.debug(“completed”)
public class EmployeeWebClient {
private static final Logger logger = LoggerFactory.getLogger(EmployeeWebClient.class);
WebClient client = WebClient.create("http://localhost:8071");
public void consumeMono() {
Mono<Employee> employeeMono = client.get()
.uri("/employees/{id}", "1")
.retrieve()
.bodyToMono(Employee.class);
employeeMono.subscribe(employee -> logger.debug("Employee: {}", employee));
logger.debug("comsumeMono thread continue");
}
public void consumeFlux() {
Flux<Employee> employeeFlux = client.get()
.uri("/employees")
.retrieve()
.bodyToFlux(Employee.class);
employeeFlux.subscribe(employee -> logger.debug("Employee: {}", employee),
err -> err.printStackTrace(),
() -> logger.debug("completed"));
}
}
当我们调用consumeMono方法签订契约消费发布者数据,会得到:
主线程签订完契约后继续执行后续逻辑,不被发布者阻塞,打印输出“comsumeMono thread continue”
发布者生产数据后,订阅者OnNext方法被调用,订阅者消费数据打印
“Employee: Employee(id=1, name=Employee 1)”.
背压机制(Backpressure Mechanism)
上篇文章说到,背压有三种策略:
- 控制发布者发送数据的速率(推荐)
- 订阅者使用缓存来存储暂时无法处理的数据
- 订阅者丢弃所有无法处理的数据
我们聚焦第一种策略(控制发布者发送数据的速率)有三种实现方式:
- 拉取方式-订阅者请求数据的时候发布者才发送
- 限制推送方式-限制发布者发布速率
- 取消订阅-订阅者可以随时取消订阅,待后续有消费能力后再次订阅
拉取方式代码示例. 我们使用subscription.request(2)每次请求2个数据.
employeeFlux.subscribe(employee -> logger.debug("Employee: {}", employee),
err -> err.printStackTrace(),
() -> logger.debug("completed"),
subscription -> {
for (int i = 0; i < 5; i++) {
logger.debug("Requesting the next 2 elements!!!");
subscription.request(2);
}
}
);
这里我们完成了一个简单的具有背压的响应式代码示例。
结束语 响应式编程作为利用现有物理资源,提供了有效提升服务响应效率的方式,通过两篇文章介绍了响应式编程的原理和WebFlux代码示例,使我们可以继续深入研究响应式编程,以便在大规模请求场景采用响应式编程作为解决用户体验的有效解决方案。